
Post 31: ¿Cuántas secuencias tenemos hasta ahora? 🤔
Published:
Pues nadie sabe con certeza.
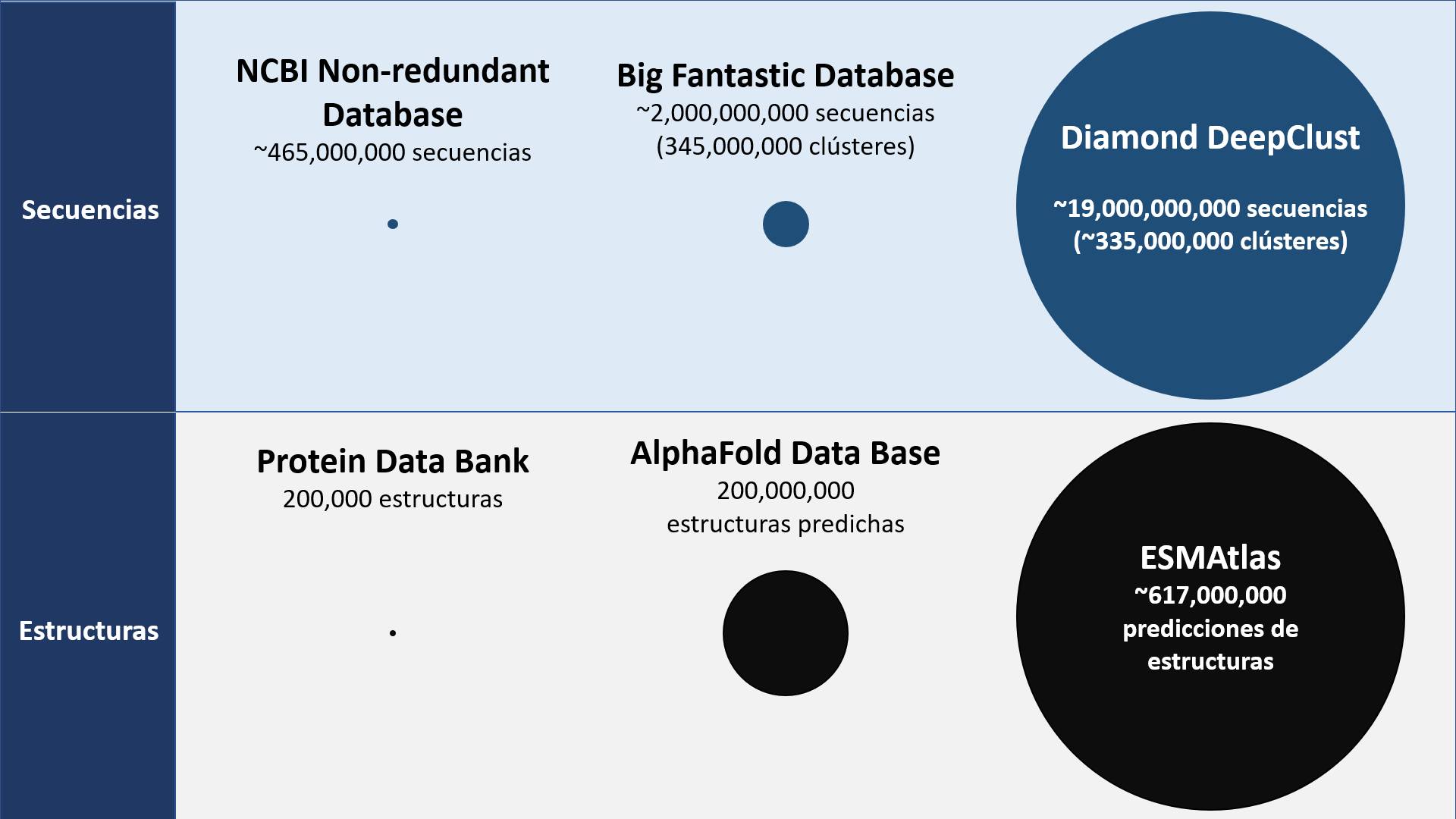
Hay muchos repositorios genómicos, cada uno con proteínas de distintos ambientes y especies. Uno de los repositorios más famosos es el de la NCBI-nr, que es el que usualmente se usa cuando hacemos un BLAST; este repositorio tiene ~465 millones de secuencias.
¿Pero, es el más grande? Para nada. Hasta donde conozco, el repositorio más grande hasta ahora, se llama DeepClust y contiene ~19 mil millones de secuencias, las cuales se pueden agrupar en ~335 millones de secuencias representativas (clústeres).
¿Y en estructuras proteícas como nos va? La Protein DataBank cuenta con ~200,000 estructuras resueltas con diferentes métodos (rayos X, Cryo-EM, etc.), pero gracias a inteligencias artificiales que predicen la estructura de las proteínas a partir de la secuencia, como lo son AlphaFold2 o ESMFold, ahora el repositorio más grande con información relativa a las estructuras es ESM-Atlas, con cosa de 617 millones de predicciones estructurales, pesando cosa de 15TB de almacenamiento.
Así que ahora datos hay … y de sobra 🤯
Refs:
- Paginas de interes:
- El articulo de DeepClust